The aide said that guys like me were ‘in what we call the reality-based community,’ which he defined as people who ‘believe that solutions emerge from your judicious study of discernible reality.’ […] ‘That’s not the way the world really works anymore,’ he continued. ‘We’re an empire now, and when we act, we create our own reality. And while you’re studying that reality—judiciously, as you will—we’ll act again, creating other new realities, which you can study too, and that’s how things will sort out. We’re history’s actors…and you, all of you, will be left to just study what we do’.
2004 feels like literally a million years ago. But this still feels prescient even today as consensus reality has gone down the toilet, and is destined to get even more fractured through synthetic realities and histories.
The supposedly senior White House official who is supposed to have made the above quote was talking in the context of “empire,” but what is an empire but a kind of hegemonic metaverse, if you will? Forced interoperability at gunpoint.
I guess what I want to say here is that, yes, being based in reality is a good thing. We shouldn’t abandon that. But the internet is a place that is not based on reality. Or if it is, it only is in the sense that a mostly invented movie might be “based on a true story.” There are things that it references which may be real things, but it blends them with the manufactured unreal.
In the case of the internet, this leads to a massive flattening of information that is nothing if not postmodern – the hyperreal. Massive distrust in the grand organizing narratives. Flattening of authority ad infinitum.
Gregory also said he appreciated that Posobiec didn’t use the video to warn about the dangers of deepfakes, which he described as “an over-used technique” that “seems to contribute to undermining trust in real media,” but to focus on a political hypothetical.
As well as Cory Doctorow’s observation that the reason people are losing trust in (some) institutions is because we’re seeing how often unworthy they are of our trust.
What is “real media” now, anyway, when so much of what passes for journalism is just clickbait or re-reporting things that happened on Twitter? And further, what are the institutions that deserve our uncritical trust?
I’m not saying there’s no objective ground truth and we should just ignore reality; I’m saying that these are not the things upon which information is based online, and that clinging to them exclusively during the rise of generative AI will make our lives very difficult in a world where anyone – not just empires (but especially empires) – can make their own “reality” that is anything but. Applying hyperreality as a lens, for me, then is a way to recognize the essential blending that happens online. And to perhaps realize that this is now our default state…
One of the most over-used of all terms within the world of content moderation, disinfo, online abuse, etc. etc. has got to be “bad actor.”
I’m sure I’ve used it myself in the past, because it is a quick convenient shorthand to collapse a potentially complex thing into. But I’m going to go out of my way to avoid using it anymore, because I’ve been feeling sort of triggered by it when I see it come up, like in that Atlantic article about conspiracy theories & generative AI (two things I happen to know something about):
These are powerful and easy-to-use programs that produce synthetic text, images, video, and audio, all of which can be used by bad actors to fabricate events, people, speeches, and news reports to sow disinformation.
I’m trying to unpack why I’ve come to hate this term, apart from mere overuse. I think it has to do also with the inherent judgement included in it, which seems to go something like: actor A did “bad” thing B, and therefore actor A is “bad.” I just think that’s an overly simplistic way to look at things.
Plenty of times it occurs that basically “innocent” actors engage in an activity online which to them in the moment might not seem all that bad, per se, but might later prove to have unintended negative consequences. Does that make them “bad”? Or does that require actual malice? (as difficult to detect as any kind of intent)
It seems to me like it might be more fruitful to put away the notion of bad actors, and even perhaps the idea of “bad actions,” because analytically it’s just not that precise . I think it would be better to instead analyze the consequences of a given action, rather than decide if the perpetrator is ontologically “bad” (which is basically unknowable). Further, even “good” actions can end up having negative consequences. So, instead of getting stuck on the action, look at what happens as a result of it. Look at the actual harms caused by things, and focus on mitigating those, instead of passing moral judgements without any specific outcome arising from it.
I like that in security contexts, there are alternative more neutral terms in use, like “threat actor.” It helps to refocus the conversation toward the specific threat —> which is generally linked to the risk of a specific negative outcome(s), instead of an unnecessarily judgemental decision about the moral character of participants.
I know the quote below is supposed to sound bad & scary (like everything online), but to me it just sounds like storytelling. In fact, it sounds like exactly the kind of hyperreal storytelling that I’ve been doing (I’m up to 69 books).
The power of AI-generated histories, Horvitz told me, lies in “deepfakes on a timeline intermixed with real events to build a story.”
The quote is from Eric Horvitz, Microsoft’s chief scientific officer. You can find Horvitz’ paper here, which I haven’t read yet. From the abstract:
Compositional deepfakes leverage synthetic content in larger disinformation plans that integrate sets of deepfakes over time with observed, expected, and engineered world events to create persuasive synthetic histories. Synthetic histories can be constructed manually but may one day be guided by adversarial generative explanation (AGE) techniques. In the absence of mitigations, interactive and compositional deepfakes threaten to move us closer to a post-epistemic world, where fact cannot be distinguished from fiction.
“Post-epistemic” seems to be here a synonym for hyperreality.
For some reason, these scenarios don’t scare me all that much – perhaps because I’m already living them from the inside out… I think it would be a mistake here to only focus on the threats and ignore the opportunities to reinvent storytelling.
I generally like Enrique Dans’ writing, but found this line to be a little bit much:
Anyone who lets a search assistant do their thinking for them deserves what they get.
It seems at this point kinda comparable to saying anyone who uses a search engine deserves what they get. I won’t say there are no issues here, obviously. But this probably isn’t the right direction to point fingers…
I went back and fished this graphic out of an old external hard drive from circa 2019. It speaks about how disinformation actors do not generally fall into neat boxes or categories, but exist along a “hybrid threat continuum.”
It occurs to me that the current work I’ve been exploring around analyzing hyperreal artifacts is really an extension of the ideas I was playing with back then. The emerging generative AI landscape has a great deal in common with disinformation, though it is also full of new threats and opportunities.
One issue I saw when I was working on related problems back then was that precisely because these actors didn’t fall into neat little boxes (and were usually hopelessly mixed together), a lot of important data was getting put by the wayside, because it didn’t quite fall into anyone’s jurisdiction in a clear cut manner. Showing hybrid threats as a continuum here was an effort to bridge those gaps, and make things actionable which might not have been before.
I wasn’t really aware of spider/radar graphs at the time, but the above would be a good candidate for using them to visualize incidents and artifacts as well.
There’s a fair amount of cross-over with studying misinformation & disinformation, to be sure. But if we join that with the broader field of hyperreality, we see it’s not only that. There’s also a heavy cross-over with synthetic media, and deepfakes, but if you map the phenomenon to a more multi-dimensional chart, it’s easy to see that there’s more to the picture.
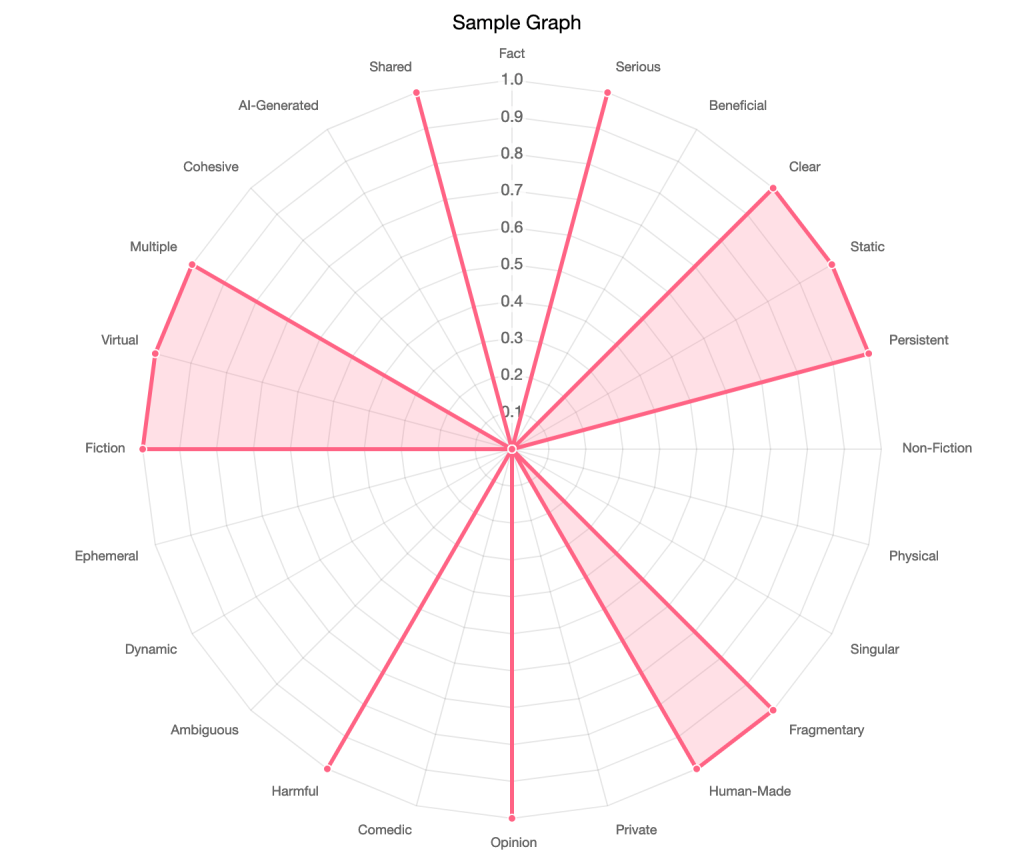
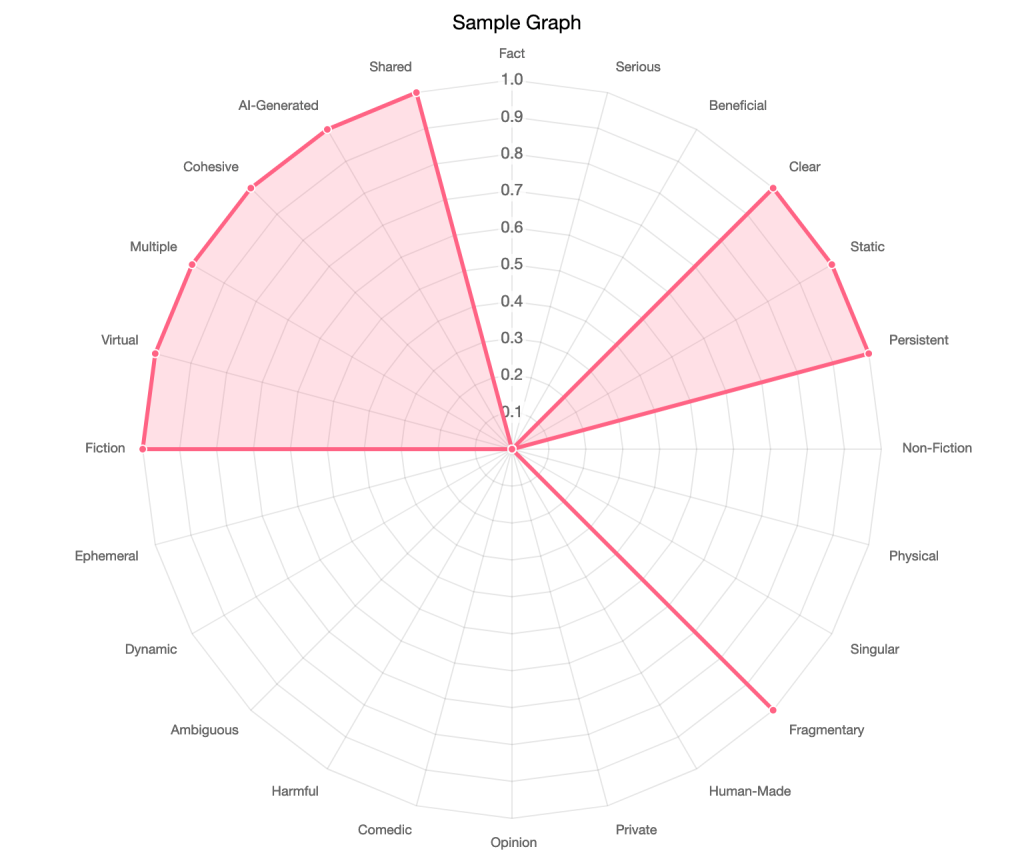
Here’s two sample graphs applying my provisional criteria (which I think need to be fine-tuned still). They use a simple 0 = none and 1 = some rating system to create imaginary profiles of two different pieces of content within this space.
I tried to make the one on the left match sort of the general outlines of a single piece of intentionally malicious disinformation. In this case, you could create that kind of content without using AI. So it might not be appropriate to lump it in with deepfakes or synthetic media, depending on your analytical objectives.
The one on the right is intended to just describe a set of AI-generated images, shared on social media. In this case, there’s no specific harm, and it’s not really expressing any specific opinion, etc.
This experiment of working up hypothetical profiles of content types is a useful one, though it makes it clear I need to tweak my data labels/dimensions/features under analysis probably.
In any event, it ends up being helpful to be able to quickly compare two different content type profiles. I can see that, okay, categories x,y,z probably are common to the vast majority of social media artifacts. And I probably am missing some other ones (a,b,c) that might help further distinguish meaningful differences… But it’s a quick V1 so I encourage others to take the best parts of this, and improve on it to fit better.
Circling back though, it’s clear to see that having a broader common framework lets us compare and contrast things across older categories in a possibly more holistic way… But I’m no closer to having a name for the approach as a whole: hyperreality studies? That doesn’t seem quite right, but at least it’s pretty neutral and doesn’t suggest any specific judgement about the object under study being good or bad, or whatever…
First, I’m applying hyperreality as my lens. You.com/chat gave me a serviceable definition of hyperreality, which is mostly paraphrased from the Wikipedia article, it seems:
Hyperreality is a concept used to describe a state in which what is real and what is simulated or projected is indistinguishable. It is a state in which reality and fantasy have become so blended together that it is impossible to tell them apart. Hyperreality is often used to describe the world of digital media, virtual reality, and augmented reality, where the boundaries between what is real and what is simulated have become blurred.
Maybe it’s just me, but this feels like a useful starting point because it speaks to shades of grey (and endless blending) as being the natural state of things nowadays. It’s now a ‘feature not a bug’ of our information ecosystems. And even though Truth might still be singular, its faces now are many. We need new ways to talk about and understand it.
Right now, people totally misunderstand what AI is. They see it as a tiger. A tiger is dangerous. It might eat me. It’s an adversary. And there’s danger in water, too — you can drown in it — but the danger of a flowing river of water is very different to the danger of a tiger. Water is dangerous, yes, but you can also swim in it, you can make boats, you can dam it and make electricity. Water is dangerous, but it’s also a driver of civilization, and we are better off as humans who know how to live with and work with water. It’s an opportunity. It has no will, it has no spite, and yes, you can drown in it, but that doesn’t mean we should ban water.
Water is also for the most part ubiquitous (except I guess during droughts & in deserts, etc.) as AI soon will be. It will be included in or able to be plugged into everything in the coming years.
Lingua Franca
Thinking of it that way, we need a new language to talk about these phenomena which will, as Jack Clark aptly pointed out, lead to “reality collapse.” That is, we need a new lingua franca, and I suspect that we have that in the concept of hyperreality; we just need to draw it out a little into a more comprehensive analytical framework.
Dimensionality
One thing I’ve observed in other analyses of the conversations emerging around AI generated content and allied phenomena is that there is a bit of reduction happening. Possibly too much. It appears to me that most discussions usually center around a very limited set of axes to describe what’s happening:
Real vs. fake
Serious vs. satire
Harmful vs. responsible
Labeled vs. unlabeled
Certainly those form the core of the conversation for a reason; they are important. But alone they give an incomplete picture of a complex thing.
Speaking as someone who has had to do the dirty work of a lot of practical detection and enforcement around questionable content, I think what we need is what might be called in machine learning a “higher-dimensional” space to do our analysis. That is, we need more axes on our graphs, because applying low-dimensional frameworks appears to be throwing out too much important information, and risks collapsing together items which are fundamentally different and require different responses.
It’s interesting once we open up this can of worms, that a more dimensional approach actually corresponds quite closely to the so-called “latent space” which is so fundamental to machine learning. Simple definition:
Formally, a latent space is defined as an abstract multi-dimensional space that encodes a meaningful internal representation of externally observed events. Samples that are similar in the external world are positioned close to each other in the latent space.
In ML, according to my understanding (I had to ask ChatGPT a lot of ELI5 questions to get this straight): for items in a dataset, we have characteristics, each of which is a feature. Then a set of features that describes an item is the feature vector. Each feature corresponds to a dimension, which is sort of a measurement of the presence and quantity of a given feature. So I higher-dimensional space uses more dimensions (to measure features of items), and a low or lower dimensional space attempts to translate down to fewer dimensions while still remaining adequately descriptive for the task at hand.
In my mind, anyway, it seems altogether appropriate to adopt the language and concepts of machine learning to analyze phenomena which include generative AI – which is really usually just machine learning. It seems to fit more completely than applying other older models, but maybe that’s just me…
Higher-dimensional analysis of hyperreality artifacts
So, what does any of that mean? To me, it means we simply need more features, more dimensions that we are measuring for. More axes in our graph. I spent some time today trying to come up with more comprehensive characteristics of hyperreality artifacts, and maxed out at around 23 or so pairs of antonyms which we might try to map to any given item under analysis.
However, when I was trying to depict that many visually, it quickly became apparent that having that many items was quite difficult to show clearly in pictorial form. So I ended up reducing it to 12 pairs of antonyms, or basically 24 features, each of which corresponds to a dimension, which may itself have a range of values.
Here is my provisional visualization:
And the pairs or axes that I applied in the above goes like this:
Fiction / Non-fiction
Fact (Objective) / Opinion (Subjective)
Cohesive / Fragmentary
Clear / Ambiguous
Singular / Multiple
Static / Dynamic
Ephemeral / Persistent
Physical / Virtual
Harmful / Beneficial
Human-made / AI generated
Shared / Private
Serious / Comedic
From my exercise in coming up with this list, I realize that the items included above as axes are not the end-all be-all here. It’s not meant to be comprehensive & other items may become useful for specific types of analysis. In fact, in coming up with even this list, I realized how fraught this kind of list is, and how many holes and how much wiggle room there is in it. But I wanted to come up with something that was broadly descriptive above and beyond what I’ve seen anywhere else.
Graphing Values
What’s the benefit of visualizing it like this? Well, having a chart helps us situate artifacts within the landscape of hyperreality; it lets us make maps. I wasn’t familiar with them before trying to understand how to represent high-dimensional sets visually, but there’s something called a radar graph or spider graph which is useful in this context.
I found a pretty handy site for making radar graphs here, and plugged my data labels (features) into it. Then, for each one, I invented a value between 0-4, which would correspond to the range of the dimension. Here’s how two different sets of values look, mapped to my graphic:
Now, these are just random values I entered to give a flavor of what two different theoretical artifacts might look like. I’m not really a “math” guy, per se, but it becomes clear right away once you start visualizing these with dummy values that you could start to make useful and meaningful comparisons between artifacts under analysis – provided you have a common criteria you’re applying to generate scores.
Criteria & Scoring
So the way you would generate real scores would be – first decide on your features/dimensions you want to study within your dataset. Then, come up with criteria that are observable in the data, and are as objective as possible. You should not have to guess for things like this, and if you are guessing a lot, your scores are probably not going to be especially meaningful. You want scoring to be repeatable and consistent, so that you can make accurate comparisons across diverse kinds of artifacts, and group them accordingly. A simple way to score would just be with a 0 for “none” and a 1 for “some.” Beyond that, you could have higher numbers for degrees or amount of which a given feature is observable in an artifact. So in the examples above, 1 could represent “a little” and 4 would be “a whole lot.”
Taking Action
Within an enforcement context – or any kind of active response, really (like for example, fact checking) – once you’ve got objective, measurable criteria that allow you to sort artifacts into groups, you can then assign each group a treatment, mitigation, or intervention – in other words, an action to take. This is usually done based on risk: likelihood, severity of harm, etc.
Anyway, I hope this gives some useful tools and mental models for people who are working in this space to apply in actual practice. Hopefully, it opens the conversation up significantly more than just trying to decide narrowly if something is real or fake, serious or satire, and getting stuck in the narrower outcomes those labels seem to point us towards.
Hyperreality is here to stay – we might as well make it work for us!
As someone who has spent a lot of time in the trenches having to analyze content for moderation purposes, I can confidently say that you can rarely truly determine intent. It’s often murky, especially when you enter into the realm of satire, trolling, disinformation, etc.
Intent is going to be hard (and intent shifts as media moves). But explore crowdsourced and decentralized smaller community-based assessment to detect, understand and assess intent as well as consequences.
It’s something I’ve seen in the “disinformation industrial complex” that, A) there’s a lot of needless quibbling even still to define misinformation vs. disinformation, and B) the difference people land on is usually one of intent (where misinformation is wrong + accidental, and disinformation is wrong + intentional – which I think is a bit lacking).
From the perspective of someone who has had to engage in thousands upon thousands of enforcement actions, I would argue that intent is opaque, and easily masked. You don’t have hundreds of hours to analyze each case, you have seconds or minutes. So the analysis necessarily must shift to consequence, as in the quote above: but more specifically, harms, in other words. Likelihood, severity, who is impacted, what is the specific harm, etc. The risk analysis matrix.
The quote above points towards community-based assessments, presumably as a way to expand the points of view leveraged to make determinations. Multi-assessor frameworks can definitely add value in difficult situations, though they can also be difficult to make proper use of in circumstances with a pressing time element (like so frequently occurs in content moderation). How does one apply this in a position as a content moderator, for example?
I’ve not used it myself (as I haven’t been active on Twitter in quite some time), but Twitter’s Community Notes aka Birdwatch seem to be an example of community-based assessment. Does it work? I’m not sure – probably depends how we define what “this is working” means, and how it could be effectively measured.
In any event, there’s more to be said here, but just wanted to establish a beachhead with some references to unpack further later on…
They refer to this as being one of the essential roles to help fill out certain aspects of a model card. For example:
the sociotechnic, who is skilled at analyzing the interaction of technology and society long-term (this includes lawyers, ethicists, sociologists, or rights advocates);
Interestingly, their use of it sounds very much like the professional discipline of Trust & Safety. (I still find it curious that T&S as a term does not seem to intersect all that much with conventional AI safety discourse.)
They elaborate later on:
The sociotechnic is necessary for filling out “Bias” and “Risks” within Bias, Risks, and Limitations, and particularly useful for “Out of Scope Use” within Uses.
Now, I believe Huggingface is maybe based in Paris (?) and as someone living in Quebec, I recognize this as being probably a “franglicism,” especially since I don’t see it coming up in this form in English on for example Dictionary.com.
The term is evidently a variation on the concept of socio-technical systems more broadly. Wikipedia’s high level definition there is not great, but ChatGPT provides a serviceable one:
Socio-technical systems refer to systems that are composed of both social and technical components, which are designed to work together to achieve a common goal or purpose. These systems typically involve human beings interacting with technology and other people in a specific context.
So even though we don’t use this word “sociotechnic” as a person who works on socio-technical systems, perhaps we do need a word that plugs that gap, and accounts for the many roles which might fill it. I think in this case, that role would be first and foremost about understanding human impacts, and then reducing or eliminating risks to human well-being. It sounds like a worthy role, whatever we call it!
Partnership on AI just released a preliminary framework around responsible practices for synthetic media, and in Section 3 for Creators, they included something I thought was interesting. They filed it under transparency, being up front about…
How you think about the ethical use of technology and use restrictions (e.g., through a published, accessible policy, on your website, or in posts about your work) and consult these guidelines before creating synthetic media.
I personally don’t think having a rigid formal policy is going to be a perfect match for artistic creations (things evolve, norms change, etc.), but the idea of just having a conversation comes from a well-intentioned place, and simply makes for a more complete discussion of one’s work, whether you’re using AI or other technologies.
Think of labeling and disclosure of how media was made as an opportunity in contemporary media creation, not a stigmatizing indication of misinformation/disinformation.
I covered a lot of this ground recently in my interview with Joanna Penn, and This AI Life, so I thought it would make sense to encapsulate the highlights of my thinking as well in written form. Consider this me doing a trial run of PAI’s suggested framework from a creator’s perspective as a “user.”
Before going further though, I want to add a slight disclaimer: I am an artist not an ethicist. My work speaks about ethics and harms related to especially AI technologies, but it is meant to be provocative and in some cases (mildly) transgressive. It is supposed to be edgy, pulpy, trashy, and “punk” in its way.
That said, here are a couple of lists of things I try to actively do and not do, that to me relate to harms & mitigation, etc. There are probably others I am forgetting, but I will add to this as I think about it.
Do:
Include information about the presence of AI-generated content
Raise awareness about the reliability & safety issues around AI by doing interviews, writing articles, blog posts, etc.
Contribute to the development of AI safety standards and best practices
Encourage speculation, questioning, critical analysis, and debunking of my work
Make use of satire and parody
Don’t:
Create works which disparage specific people, or discriminate or encourage hate or violence against groups of people
Use the names of artists in prompts, such that work is generated in their signature style
Undertake projects with unacceptable levels of risk
Reflections
There are a few sections of the PAI framework that seem a bit challenging as someone new to all of this discussion, applying the lens that I am.
Aim to disclose in a manner that mitigates speculation about content, strives toward resilience to manipulation or forgery, is accurately applied, and also, when necessary, communicates uncertainty without furthering speculation.
I think I covered this in a few places now, the Decoder piece maybe, the France 24 interview… In short: I want to encourage speculation, ambiguity, uncertainty; that’s hyperreality, that’s the uncanny valley. As an artist, that’s what’s exciting about these technologies, that they break or blend boundaries, or ignore them altogether. And like it or not, that’s the world we’re heading into as a massively splintered choose-your-own-reality hypersociety.
Yes, I think it’s necessary all these industry standardization initiatives are developed, but I guess I’m also interested in Plan B, C, D, or, in short: when the SHTF. I guess my vision is distorted because I’ve seen so much of the SHTF working in the field that I have. But someone has to handle when everything always goes wrong, after all, because that’s reality + humanity.
From PAI’s document, this one also I have a hard time still squaring with satire & parody:
Disclose when the media you have created or introduced includes synthetic elements especially when failure to know about synthesis changes the way the content is perceived.
If you’ve read the Onion’s Amicus Brief, it persuasively (in my mind, as a satirist, anyway) argues that satire should not be labeled, because its whole purpose is it inhabits a rhetorical form, which it then proceeds to explode – turning the assumptions that lead there inside out. Its revelatory in that sense. Or at least it can be.
So in my case, I walk the line on the above recommendation. I include statements in my books explaining that there are aspects which may have been artificially generated. I don’t say which ones, or – so far – label the text inline for AI attribution (though if the tools existed to reliably do so, I might). I want there to be easter eggs, rabbit holes, and blind alleys. Because I want to encourage people to explore and speculate, to open up, not shut down. I want readers and viewers to engage with their own impressions, understanding, and agency, and examine their assumptions about the hyperreal line between reality and fiction, AI and human. And I want them to talk about it, and engage others on these same problems, to find meaning together – even if its different from the one I might have intended.
It’s a delicate balance, I know; a dance. I don’t pretend to be a master at it, just a would-be practitioner, a dancer. I’m going to get it wrong; I’m going to make missteps. I didn’t come to this planet to be some perfect paragon of something or other; I just came here to be human like all the rest of us. As an artist, that’s all I aim to be, and over time the expression of that will change. This is my expression of it through my art, in this moment.